
 What is Apache Spark.
What is Apache Spark.
Spark provides an application programming interface centered on a data structure called the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.
Spark is better than MapReduce and Hadoop because it is much faster and has as well some benefits like interactive processing and machine learning tool, which allows to have predictive analytics's.
Spark structure:
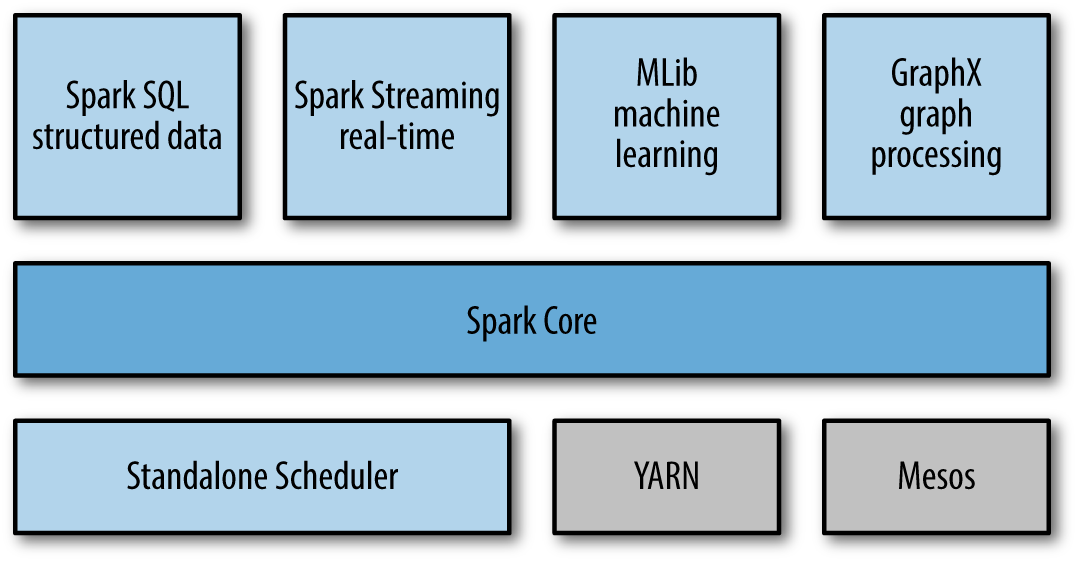
Spark Core: contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems. Spark Core provides many APIs for building and manipulating RDD collections. RDD is a collection of Objects that are immutable and their operations are lazy; fault-tolerance is achieved by keeping track of the "lineage" of each RDD, the sequence of operations produced it, so that it can be reconstructed in the case of data loss.
Spark SQL: is a component that introduces a new data abstraction called DataFrames, which provides support for structured and semi-structured data. Spark SQL provides a domain-specific language to manipulate DataFrames. It also provides SQL language support, with command-line interfaces and ODBC/JDBC server.
It allows querying data via SQL as well as the Apache Hive variant of SQL—called the Hive Query Language (HQL)—and it supports many sources of data, including Hive tables, Parquet, and JSON.
Spark Streaming: is a component that enables processing of live streams of data. Spark Streaming provides an API for manipulating data streams that closely matches the Spark Core’s RDD API. This design enables the same set of application code written for batch analytics to be used in streaming analytics, on a single engine.
MLlib Machine Learning Library: is a distributed machine learning framework on top of Spark Core
provides multiple types of machine learning algorithms, including classification, regression, clustering, and collaborative filtering, as well as supporting functionality such as model evaluation and data import.
It also provides some lower-level ML primitives, including a generic gradient descent optimization algorithm. All of these methods are designed to scale out across a cluster which simplifies large scale machine learning pipelines, including:
- summary statistics, correlations, stratified sampling, hypothesis testing, random data generation[10]
- classification and regression: support vector machines, logistic regression, linear regression, decision trees, naive Bayes classification
- collaborative filtering techniques including alternating least squares (ALS)
- cluster analysis methods including k-means, and Latent Dirichlet Allocation (LDA)
- dimensionality reduction techniques such as singular value decomposition (SVD), and principal component analysis (PCA)
- feature extraction and transformation functions
- optimization algorithms such as stochastic gradient descent, limited-memory BFGS (L-BFGS)
GraphX: is a library for manipulating graphs and performing graph-parallel computations.
It also provides various operators for manipulating graphs e.g. subgraph and mapVertices and a library of common graph algorithms, it also provides an optimized runtime.RDD - Resilient Distributed Dataset, is an interface to data and provide an contract between data and spark, they can be classified in two main types - Transformations and Actions.
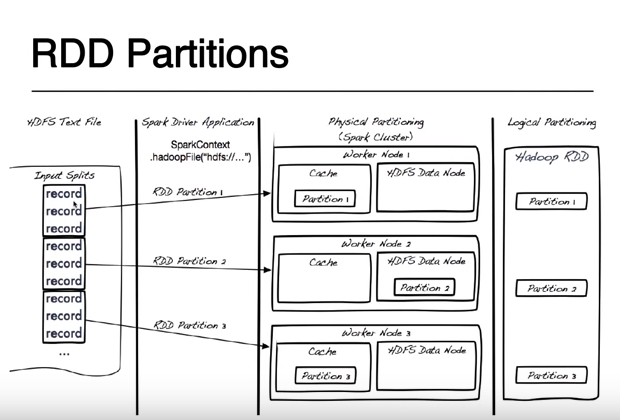
Persistance - it is not all the time persisted in the disk the most powerful way to store is cache (ram) but it has cons because all the time when on RDD is performed an action or transformation then entire RDD is recreated and recomputed. The lineage concept describe the process how HDFS file input is transformed to a new RDD e.g. HadoopRdd->FiltedRDD->MappedRDD->ShuffledRDD ... .
Global variables:
- Accumulator is a tool which enables nodes communicate with each other via driver.
- Broadcast is a distributed cache across nodes.
- StatsCounter is a tool which allows to create a statistic based on data in all nodes eg. count sum min...
- DataFrames is a data structure framework same idea like relational data base.
Yarn based Architecture
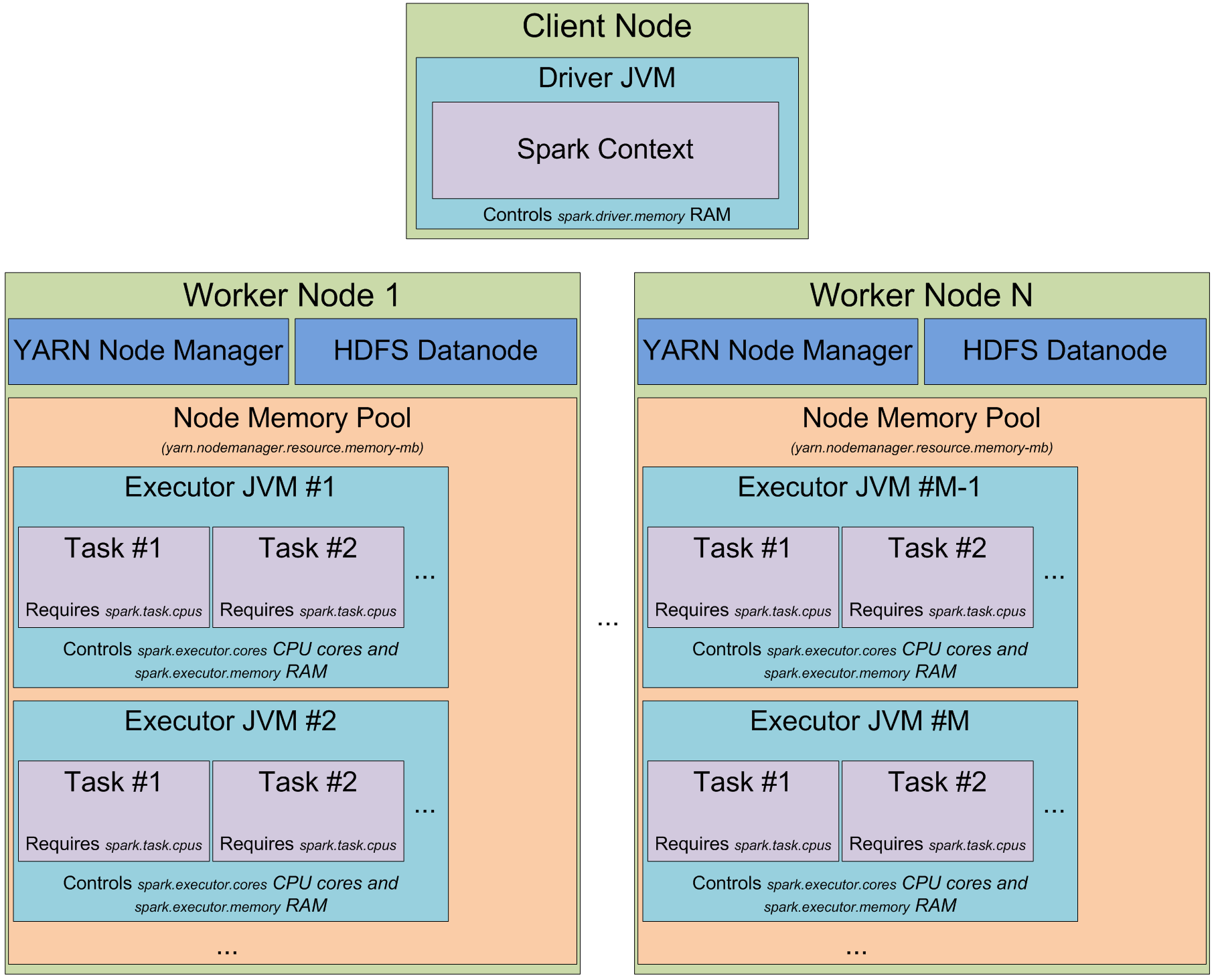
Tuning can be done for different aspects eg. job tuning(increase memory) or GC, MemoryUsage, Level of parallelism, data structure tuning, more details about tuning are available on spark docs page: http://spark.apache.org/docs/latest/tuning.html
Intro to Spark Streaming | NewCircle Training
Application in real life.